En entradas anteriores, realizamos Análisis Exploratorio de Datos (EDA) y estimamos un modelo de regresión lineal utilizando el dataset Houses in London. A continuación explicamos brevemente de qué se tratan y cómo podemos validarlos utilizando el modelo previamente estimado. Revisaremos de qué trata cada supuesto y comprobaremos si en nuestro modelo se cumplen.
Independencia de los errores
Se considera que los errores son independientes en el sentido probabilístico. Los errores son los residuales o diferencia entre la estimación y los datos reales. Para comprobarlo, utilizamos la prueba de hipotesis de Durbin-Watson, la cual asume en su hipotesis nula que los errores no están autocorrelacionados. La librería que utilizamos es “car” y la función es durbinWatsonTest. En este caso, para rechazar la hipotesis nula de no autocorrelación, esperamos ver un p-value (o valor p) menor a 0.05 para un nivel de significancia de 0.05. Al haber obtenido un valor de 0.098, no podemos rechazar la hipótesis nula, por lo que concluimos que los errores son independientes.
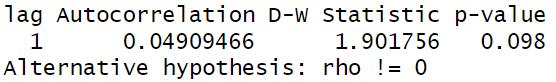
Homoscedasticidad
La varianza de los errores es constante para todos los valores de la varaiable independiente. Para comprobar este supuesto, utilizamos la librería “performance”, la cual puede llamarse de manera individual o llamando a la colección de librerías contenidas en “easystats”.La función a utilizar es model_performance, la cual nos indica fácilmente si este supuesto se cumple o no. Para el modelo que estamos analizando, este supuesto no se cumple .

Otra forma de comprobar este supuesto, es la inspección visual, pero no es muy recomendable, así que utilizaremos la prueba de Breusch-Pagan, la cual tiene como hipótesis nula que los errores son homoscedásticos. De nueva cuenta, rechazamos que los erroes sean homoscedásticos, basándonos en el valor p de la prueba.

Normalidad
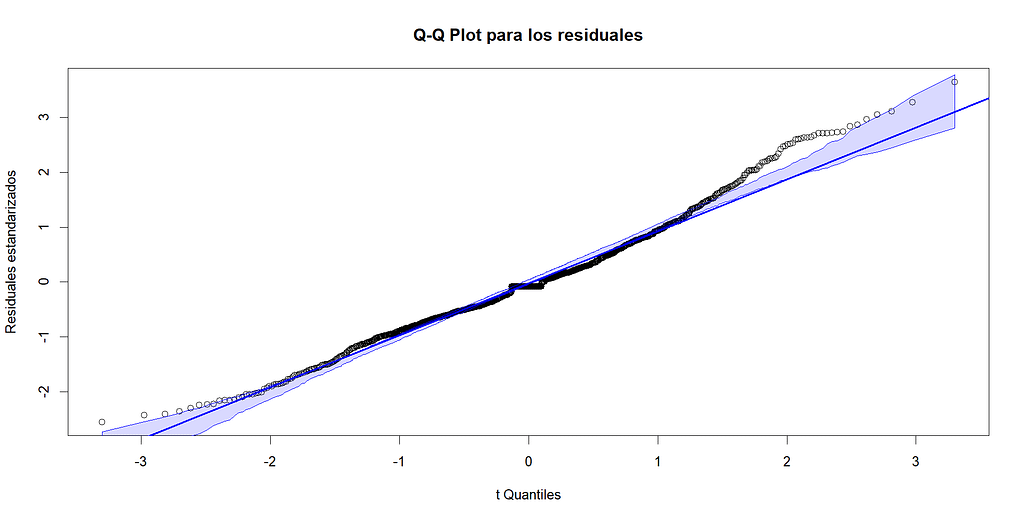
Se asume que los errores siguen una distribución normal de probabilidad con media 0 y varianza constante. La primera comprobación que hacemos es visual, buscando la forma de campana característica de la distribución normal. Se utiliza la función qqplot, la cual nos genera un gráfico de cuantil cuantil o Q-Q Plot. En este tipo de gráfico, si los datos o los residuales siguen una distribución normal, los datos del centro se encontrarán sobre una línea recta y los datos de los extremos se despegarán un poco. Cuando los residuales no siguen no siguen una distribución normal, los datos se despegan de la recta en puntos distintos. En este caso, podemos apreciar que los datos en el centro de la línea que no se ajustan a esta.
Como la comprobación visual no es suficiente, utilizaremos la funcion check_normality de la librería “performance” , la cual nos dirá automáticamente si los residuales son normales o no. En este caso, se detectó no normalidad.

Otra forma de comprobar la normalidad de los residuos, es la prueba de Shapiro-Wilk. Esta prueba tiene como hipótesis nula que los datos siguen una distribución normal. A un nivel de significancia del 0.05, el resultado para nuestros residuales indica que no hay normalidad, mismo resultado que con la prueba anterior.

El hecho de que algunos supuestos de la regresión no se cumplan, implica que los resultados puedan estar sesgados o afectar los intervalos de confianza y afectar las inferencias y predicciones. Las soluciones a la violación de estos supuestos se abordarán en otras entradas.
El código completo para reproducir este ejemplo está en mi GitHub
Ayúdame a seguir creando contenido