Analicemos el dataset Houses in London
El análisis exploratorio de datos (EDA, por sus siglas en inglés) ayuda a identificar anomalías y patrones en conjuntos de datos y es un paso previo antes de la aplicación de un modelo. El EDA nos permite conocer las características generales de un conjunto de datos, visualizarlo y decidir cómo proceder en etapas posteriores. Hagamos un ejercicio de EDA utilizando el dataset Houses in London, disponible en Kaggle. Este conjunto de datos muestra las características de 1000 viviendas en Londres e incluye el vecindario en el que se encuentra cada casa, el número de pisos, baños, recámaras y si cuenta con jardín y garage y balcón, además de otras características como el tipo de calefacción y de propiedad, los años de construcción y el estilo y material de la misma, los metros cuadrados y el precio en libras de cada propiedad.
Las variables contenidas en el conjunto de datos son de dos tipos: cuantitativas y cualitativas. Las variables cuantitativas básicamente son números y un ejemplo de ellas para este conjunto de datos es el precio de cada vivienda y los metros cuadrados de cada una. Las variables cualitativas expresan características de un individuo, o en este caso de cada propiedad. Ejemplos de estas variables son el vecindario, el estilo, el material y el tipo de propiedad (apartamento, casa unifamiliar, casa adosada). Pero existen variables cualitativas que se expresan con un número y esto puede prestarse a confusiones. Por ejemplo, en el caso de la variable que indica el número de recámaras, el hecho de que veamos un número 3 indica que la casa tiene esa característica. Otro ejemplo es el número de baños. Algo similar pasa en el famoso conjunto de datos mtcars (incluido en R), en el que el número de cilindros es una variable cualitativa y no cuantitativa, ya que indica las características del coche y si tiene 4, 6 u 8 cilindros.
Comencemos con algo fácil para analizar este dataset. ¿En qué vecindario se encuentran la mayoría de las propiedades?. Con la función table podemos obtener el conteo por vecindario. Vemos que hay 10 vecindarios consideros: Camden, Chelsea, Greenwich, Islington, Kensington, Marylebone, Notting Hill, Shoreditch, Soho y Westminister. El vecindario con el mayor número de viviendas es Kensington con 114, seguido por Marylebone con 113 propiedades. El vecindario con el menor número de propiedades es Shoreditch con 89. Esta es la salida de la consola de R, pero también se puede hacer una gráfica. El gráfico apropiado es es uno de barras, que se puede elaborar utilizando la función barplot.default, pero este tipode visualización no luce muy profesional. Comparemos con otras alternativas.

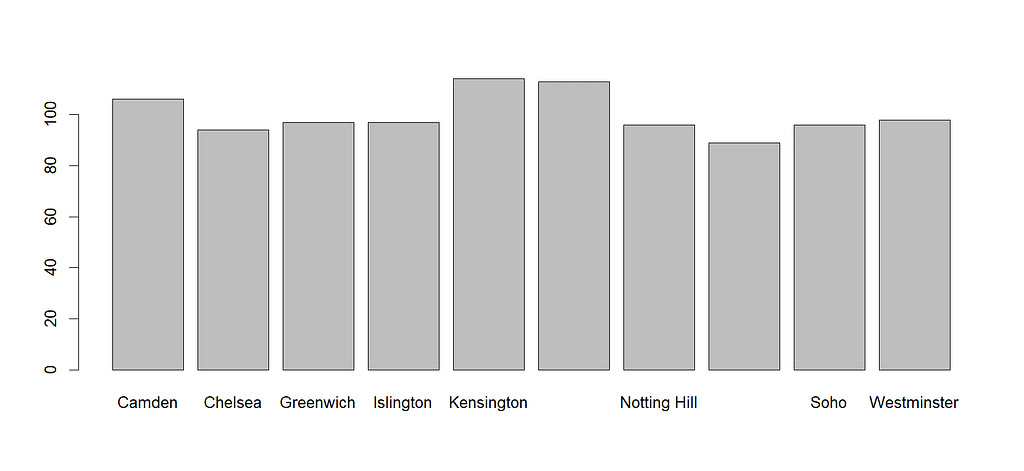
La librería para visualización más popular es ggplot2 y la función qplot que permite ajustar colores, fondo, eje y colores de relleno en las barras. Es notorio que el gráfico mejora, sobre todo porque aparecen todos los nombres de los vecindarios.
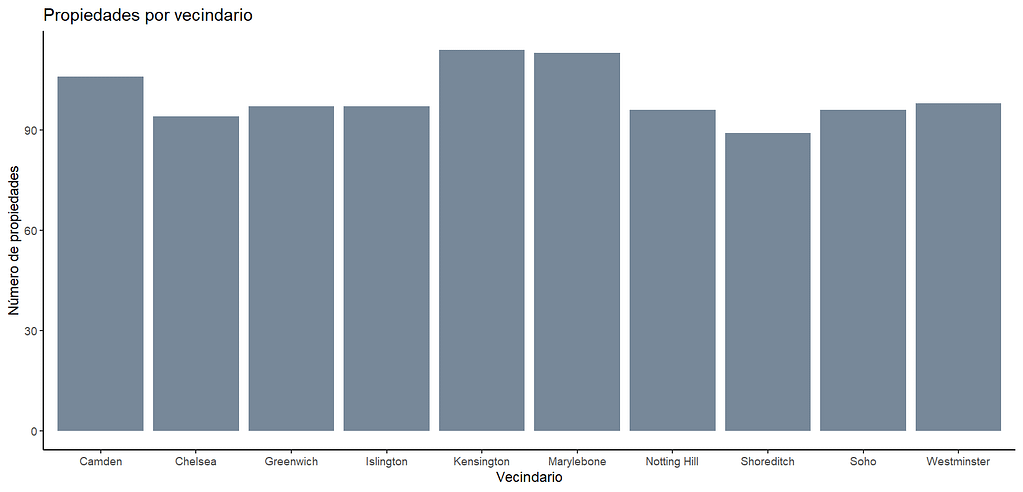
Ahora queremos saber cuál es el número de recámaras más popular, así que haremos lo mismo. Se puede observar que 3 recámaras se repite con más frecuencia.
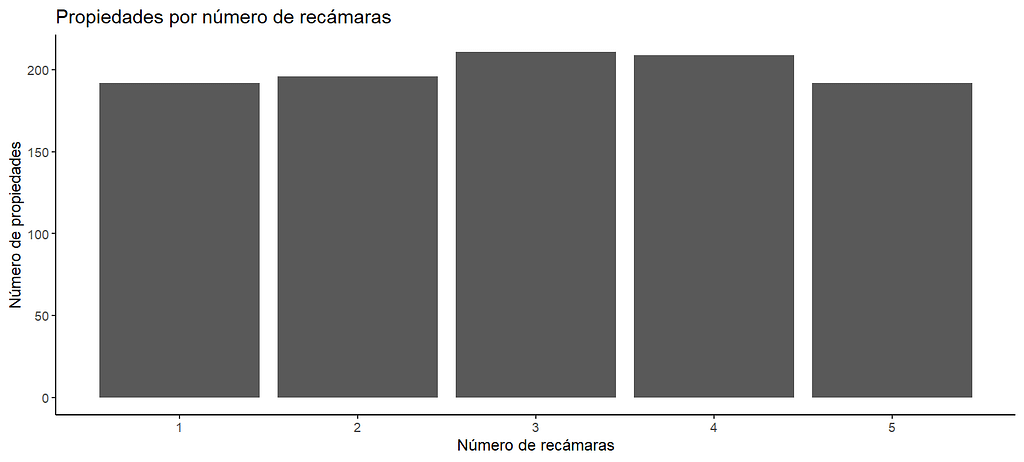
Ahora comencemos con el análisis de las variables cuantitativas. Comencemos por el precio. Estamos interesados en saber cuál es precio promedio y los precios mínimo y máximo de este listado. Esto se hace fácilmente con la función summary. El valor medio de las viviendas del listado es 1,840,807 libras, mientras que los valores mínimo y máximo son 386,666 y 4,980,000 respectivamente. Además de estos datos, la función summary nos proporciona otros valores: la mediana, el primer cuartil y el tercer cuartil. Estos números sirven para darnos cuenta de la distribución de los datos y sirven como base para hacer el gráfico de caja o boxplot, que también nos ayuda a identificar valores atípicos.
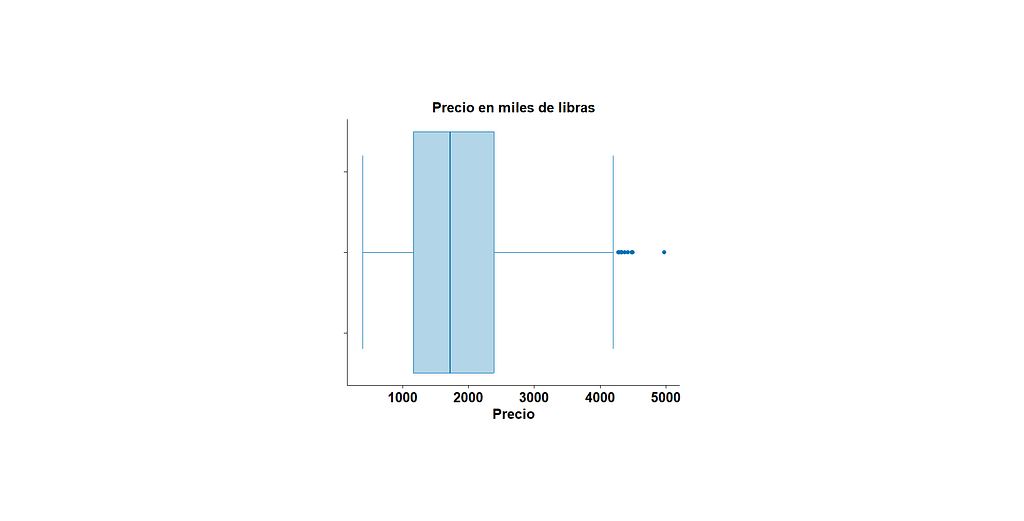
Los valores atípicos aparece al lado derecho como puntos fuera de la caja. Los “bigotes” (las líneas que sobresalen de la caja) marcan los límites entre los valores atípicos y el resto de los valores. La línea vertical que cruza la caja representa la mediana. Si tuviéramos datos que siguen una distribución normal, esta línea estaría exactamente en el medio de la caja. En el caso en el que no se encuentre centrada, la distribución de datos podría estar sesgada y podría no ser normal, pero para asegurarlos se tiene que hacer pruebas de normalidad que no abordaremos en esta ocasión. Este gráfico fue hecho con la librería tidyplots
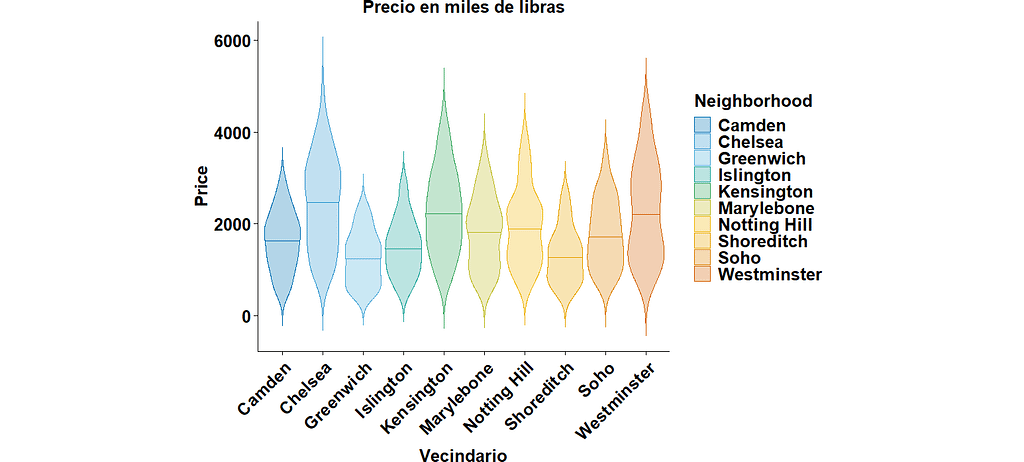
Si quieremos darnos una mejor idea de si nuestros datos siguen una distribución normal o de campana, podemos utilizar los gráficos de violín. Si tuviéramos una distribución normal, la mayoría de los datos se concentrarían en el centro del violín, pero si tenemos una muestra con dos modas o sesgada, los violines no tendrían una forma simétrica. En este caso, estamos utilizando los datos de precio agrupados por vecindario y podemos ver como solamente los violines de Islington y de Kensington tienen una forma simétrica. Por el contrario, el violín de Westminister tiene concentraciones en sus dos extremos, mientras que Soho concentra más datos en la parte inferior del violín. Nuevamente recordamos que esto no significa que los datos no sigan una distribución normal, lo cual descartamos solamente con prueba de hipótesis. Este gráfico también fue hecho con la librería tidyplots
Correlación
Primero tenemos que definir qué y qué no es la correlación. La correlación es una medida de asociación entre dos variables. Nos indica si estas variables están relacionadas o no. Esta medida puede tomar valores entre -1 y 1. La correlación se interpreta en dos partes. Primero, el valor. Un valor cercano a 1 indica una relación fuerte. Un valor de 0 indica que no hay relación. La segunda parte de la interpretación es el signo. Una correlación negativa indica que si una variable aumenta, la otra disminuye, mientras que en el caso de una correlación positiva, ambas variables se moverán en la misma dirección. Esto significa que si una variable aumenta, la otra también lo hará. Es importante aclarar algo: CORRELACIÓN NO IMPLICA CAUSALIDAD. Es decir, si tengo un par de variables asociadas, no quiere decir que una cause a la otra.
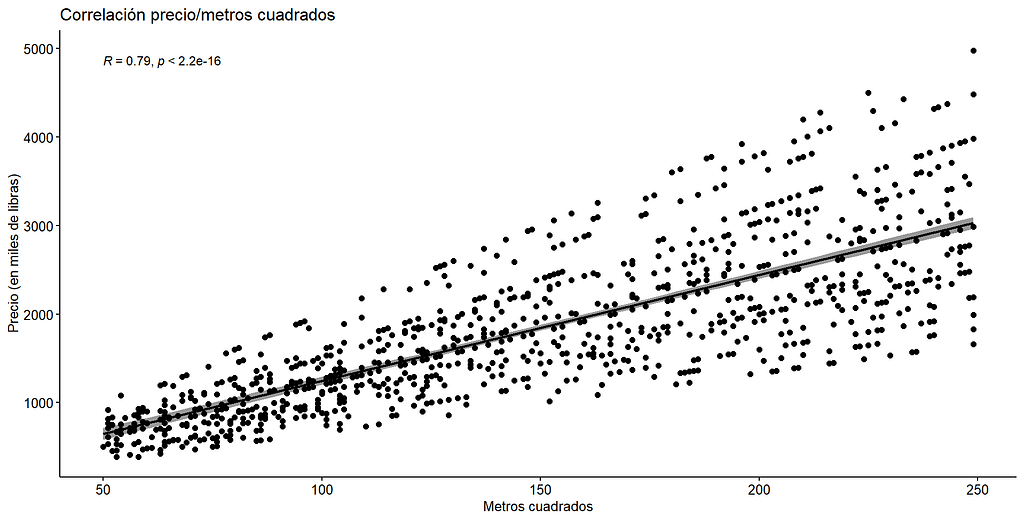
Como ejemplo, trataremos de establecer si existe o no relación entre el precio de la vivienda y los metros cuadrados. En este caso, el valor de R = 0.79 indica que la relación es positiva, es decir que si sube el precio, también lo hará el número de metros cuadrados y viceversa. Este valor nos indica que la relación es fuerte, mientras que el valor de p indica que la relación es significativa. El hecho de que los puntos de datos “apunten” hacia arriba también nos indica de la relación positiva, pero si tuviéramos una relación negativa, los datos apuntarían hacia abajo, mientras que si no hubiera relacion, los datos aparecerían siguiendo una línea horizontal. La librería utilizada para este gráfico es ggpubr.
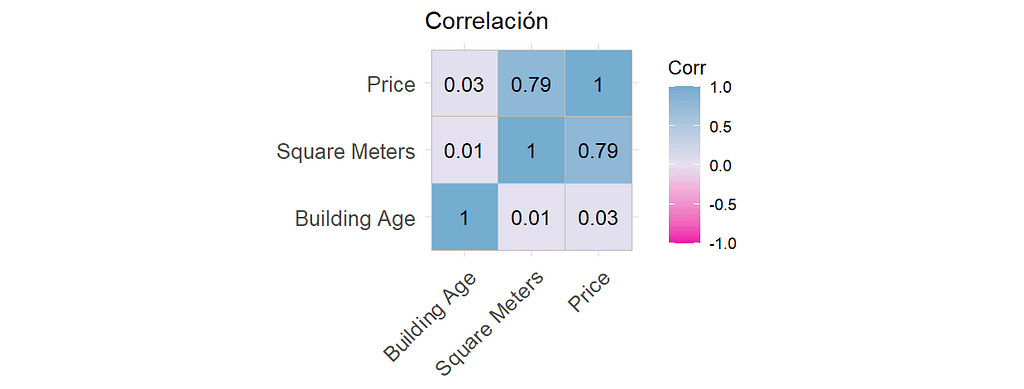
Saber si existe correlación entre nuestros datos nos ayuda para determinar si más adelante será pertinente elaborar modelos de regresión utilizando los datos correlacionados, ya que si esta no existe, el modelo de regresión no servirá. Si queremos una visualización más amigable, podemos elaborar una matriz de correlaicón con la librería ggcorrplot. En este caso, utilizamos las e variables númericas (precio, edad de la construcción y metros cuadrados). El resultado de 0.79 de coeficiente de correlación entre el precio de las casas y los metros cuadrados vuelve a observarse, pero la correlación entre los metros cuadrados y la edad de la construcción prácticamente no tienen relación.
El código completo para reproducir estos gráficos se encuentra disponible en mi Github