La regresión lineal es una de las herramientas más importantes en el toolkit de un científico de datos. De la comprensión de este modelo se deriva el entendimiento de modelos más complejos como el modelo de regresión lineal múltiple, además de que su comprensión vuelve más fácil entender otros modelos como los VAR (modelos de vectores autorregresivos). Pero primero debemos entender qué hace y para qué sirve.
La regresión lineal simple comprende dos variables: una dependiente (denotada por la letra y) y otra explicativa o independiente (la variable x). La variable y tomará valores dependiendo de los valores que tome la variable y. Esta relación se expresa por medio de una ecuación que representa una recta con pendiente positiva o negativa. La ecuación que representa esta recta es la siguiente
")
En esta ecuación, alfa es el intercepto (el valor que y toma cuando x=0) y beta es la pendiente, mientras que x puede tomar culaquier valor. Esta ecuación se calcula mediante un procedimiento matemático conocido como Mínimos Cuadrados Ordinario (MCO) o OLS (Ordinary Least Squares) por sus siglas en inglés. Usaremos el dataset Houses in London para hacer un ejemplo de regresión simple en R, en el que el precio será la variable dependiente, mientras que la variable independiente serán los metros de cada propiedad. Puedes ver el análisis de este dataset aquí. En ese análisis se determinó que existe una correlación entre el precio de venta y los metros cuadrados, por lo que se puede construir un modelo de regresión.
Para la creación del modelo de regresión lineal no se requiere ninguna librería en particular, pero para analizar el modelo se utiliza easystats, una colección de librerías enfocadas en visualización, análisis estadístico y elaboración de reportes estadísticos comprensibles y de fácil interpretacion.
El modelo de regresión utiliza la función lm de la librería base y como resultado, se obtiene la ecuación que representa la recta de la relación entre las dos variables, el precio y los metros cuadrados. La salida en la consola de R es esta:

La primera línea del resultado es la misma que esecificamos utilizando lm. La siguiente parte, que aparece como “Residuals” se refiere a las diferencias entre los puntos de datos y la recta calculada. Se muestra lo que se conoce como “El Resumen de los 5 Números”, que muestra el dato más pequeño, el más grande, la mediana y los cuartiles 1 y 3. La parte de “Coefficients” nos da los valores calculados para el intercepto (alfa) y beta, que en este caso aparece como SQM (los metros cuadrados). También se muestran los errores estándar para ambos casos, el estadístico de prueba y su valor p. La última parte muestra el error estándar para todo el modelo de regresión, los grados de libertad (n-2) y el coeficiente de R2, el cual representa la parte de la varianza capturada por el modelo. Este último valor debe estar entre 0 y 1, representando un mayor ajuste del modelo conforme este valor se acerque a 1. En este caso, nuestro modelo logra capturar el 62.51% de la varianza. El valor F y su valor p, indican que el modelo es significativo.
Esta interpretación puede hacerse con los conocimientos básicos acerca del modelo de regresión lineal, pero en R existe la colección de librerías “easystats” de la cual ya teníamos una entrada anterior que puedes revisar aquí. El reporte indica que el efecto de los metros cuadrados es positiva y significativa considerando un intervalo de confianza del 95%.

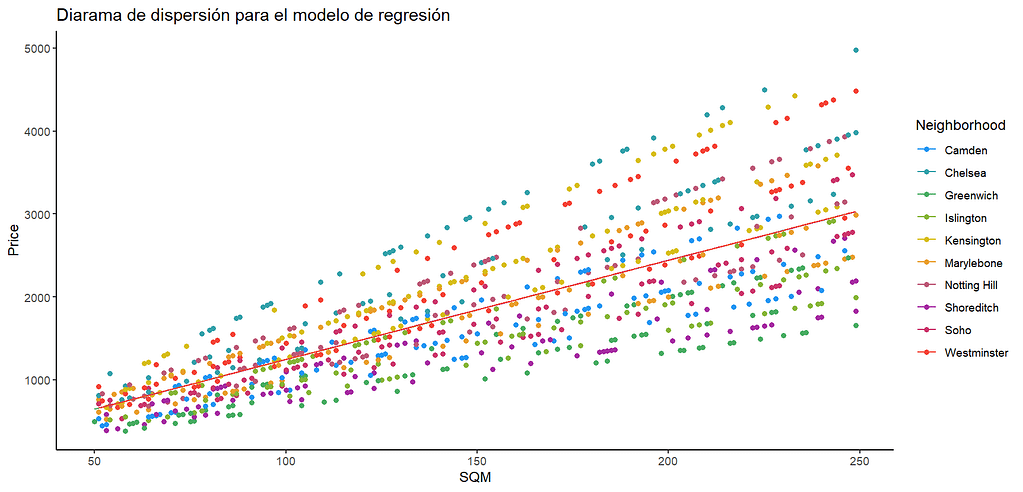
Hemos obtenido así un modelo de regresión significativo y que explica una proporción sustancial de la varianza, pero falta un último paso: la revisión de los supuestos acerca de los residuales, que tendremos en una entrada posterior. El diagrama de dispersión y la recta ajustada encontrada por el modelo, se ven así. La recta de mejor ajuste está marcada por la línea naranja.
Apóyame a seguir creando contenido
Obtén el código para replicar el EDA y el modelo de regresión para Houses in London aquí